

































The competition in the AI landscape intensifies with Claude 3, purported to possess capabilities approaching those of a human
Anthropic introduced Claude 3 on Monday, a trio of AI language models akin to those empowering ChatGPT.

Anthropic introduced Claude 3 on Monday, a trio of AI language models akin to those empowering ChatGPT. The claim from Anthropic is that these models establish new benchmarks in the industry across various cognitive tasks, even reaching "near-human" capabilities in certain scenarios. Claude 3 is accessible through Anthropic's website, with the most advanced model requiring a subscription. Developers can also access it through an API.
The three models, Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus, differ in complexity and parameter count. While Sonnet is available for free on the Claude.ai chatbot, Opus is exclusive to Anthropic's web chat interface for subscribers of the $20 per month "Claude Pro" service. All three models boast a 200,000-token context window, reflecting their capacity to process fragments of words simultaneously.
This release follows Anthropic's previous launches of Claude in March 2023 and Claude 2 in July of the same year, with each iteration showing incremental advancements in capability and context window length, occasionally surpassing OpenAI's models. With Claude 3, Anthropic aims to compete with OpenAI's latest models in terms of performance, although expert consensus is yet to be established, acknowledging the potential for selective presentation of AI benchmarks.
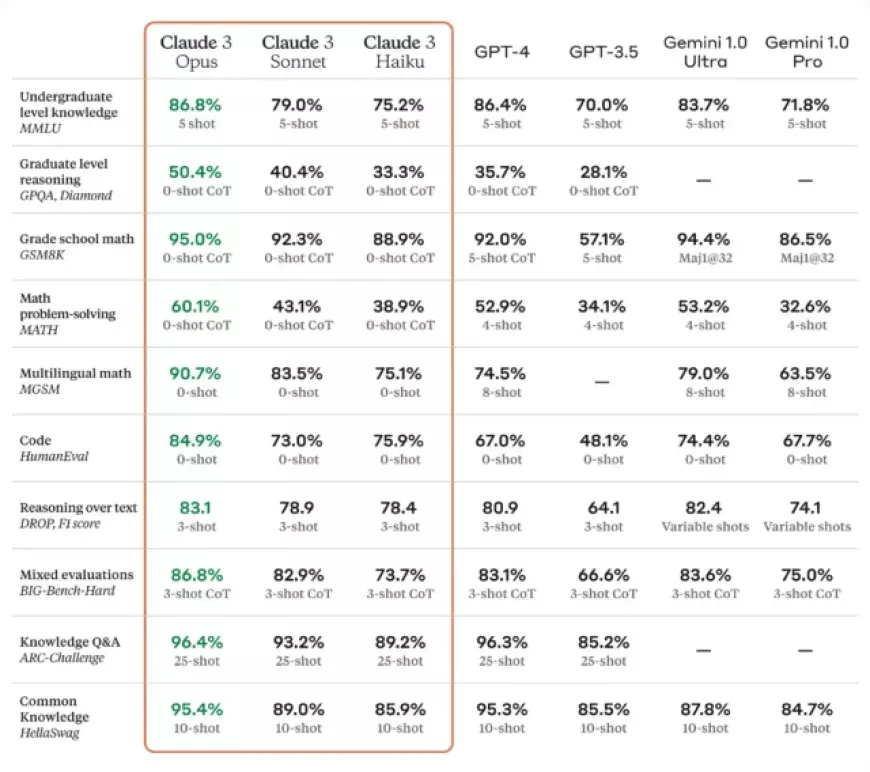
Claude 3, particularly the Opus model, is claimed to exhibit advanced performance in various cognitive tasks such as reasoning, expert knowledge, mathematics, and language fluency. Anthropic asserts that the Opus model achieves "near-human levels of comprehension and fluency on complex tasks." While this claim suggests high proficiency in specific benchmarks, it doesn't imply Opus possesses general intelligence comparable to humans. The company contends that Opus outperforms GPT-4 on 10 AI benchmarks, including MMLU (undergraduate level knowledge), GSM8K (grade school math), HumanEval (coding), and HellaSwag (common knowledge).
Some victories are narrow, while others, like the 84.9% on HumanEval compared to GPT-4's 67.0%, represent substantial leads. However, the interpretability of these benchmarks for end-users remains challenging, as AI researcher Simon Willison notes that model performance on benchmarks doesn't necessarily indicate the user experience. Despite this, the achievement of outperforming GPT-4 on widely used benchmarks is considered a significant milestone.
A wide range in price and performance
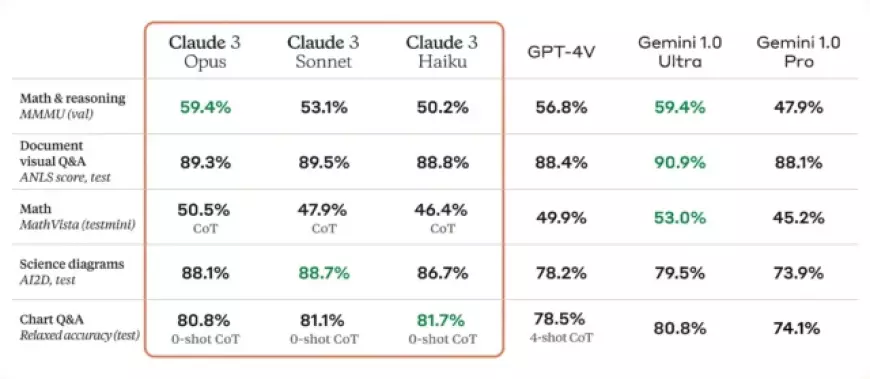
In contrast to its forerunner, Claude 3 models exhibit advancements over Claude 2 in various aspects, including analysis, forecasting, content creation, code generation, and multilingual conversation. Additionally, these models purportedly boast improved vision capabilities, enabling them to interpret visual formats such as photos, charts, and diagrams, akin to GPT-4V (found in subscription versions of ChatGPT) and Google's Gemini.
Anthropic underscores the increased speed and cost-effectiveness of the three Claude 3 models compared to both prior iterations and rival models. Opus, the largest model, is priced at $15 per million input tokens and $75 per million output tokens. Sonnet, the middle model, costs $3 per million input tokens and $15 per million output tokens, while Haiku, the smallest and fastest model, is set at $0.25 per million input tokens and $1.25 per million output tokens. In contrast, OpenAI's GPT-4 Turbo API is priced at $10 per million input tokens and $30 per million output tokens, while GPT-3.5 Turbo is $0.50 per million input tokens and $1.50 per million output tokens. The competitive pricing of the unreleased Haiku model stands out, according to AI researcher Simon Willison, while the highest-quality Opus model is noted for its higher cost.
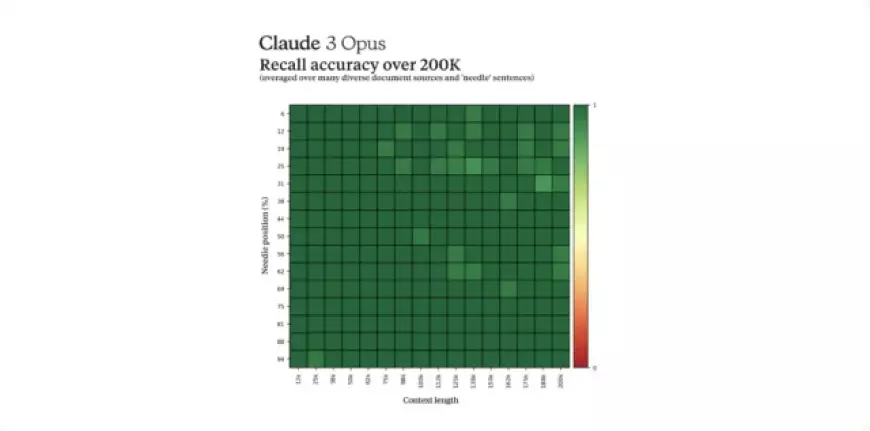
In additional points of interest, the Claude 3 models can reportedly manage up to 1 million tokens for specific clients, akin to Gemini Pro 1.5. Anthropic asserts that the Opus model achieved nearly flawless recall in a benchmark test across this extensive context size, surpassing 99 percent accuracy. Furthermore, the company claims that the Claude 3 models are less likely to reject harmless prompts and exhibit higher accuracy while minimizing incorrect responses.
As indicated in a model card accompanying the models, Anthropic attributes the capability advancements of Claude 3, in part, to the utilization of synthetic data during the training process. Synthetic data involves internally generated data using another AI language model, serving as a means to enhance the depth of training data and represent scenarios that may be lacking in a scraped dataset. AI researcher Simon Willison emphasizes the significance of the synthetic data approach.
Anthropic has intentions to roll out frequent updates for the Claude 3 model family in the upcoming months, introducing new features such as tool use, interactive coding, and "advanced agentic capabilities." The company emphasizes its commitment to ensuring that safety measures align with the advancements in AI performance and assures that the Claude 3 models "pose negligible potential for catastrophic risk at this time."
As of now, the Opus and Sonnet models are available through Anthropic's API, while Haiku is set to be released soon. Sonnet is also accessible through Amazon Bedrock and is in private preview on Google Cloud's Vertex AI Model Garden.
A word about LLM benchmarks
Upon subscribing to Claude Pro and conducting informal tests with Opus, it was observed that Opus exhibits a level of capability comparable to ChatGPT-4. While it struggles to generate original dad jokes (relying on scraped content from the web), it performs well in summarizing information, composing text in various styles, and logically analyzing word problems. Confabulations, or the generation of incorrect information, appear to be relatively low, with only occasional slips observed when discussing more obscure topics. In a field where quantifiable benchmarks are customary, the absence of definitive pass/fail outcomes can be frustrating, emphasizing the subjective nature of AI evaluation.
AI benchmarks pose challenges as the effectiveness of AI assistants depends on various factors, including prompts used and the conditioning of the underlying AI model. AI models may perform well on specific tests but struggle to generalize capabilities to novel situations. Additionally, the subjective nature of AI assistant effectiveness makes it challenging to quantify success, as tasks can span diverse intellectual fields. This variability is not unique to Claude 3 but applies to all major language models from vendors like Google, OpenAI, and Meta. Each model has its strengths and weaknesses, which can be addressed through specific prompting techniques. Therefore, claims of outperforming other models should be approached with caution, and personal testing is crucial to determine the suitability of a model for a particular application.






